
Introduction
Accurately predicting house prices is critical in real estate, finance, and urban planning, where it guides investment decisions and policy-making. This project leverages the Boston Housing dataset to build a linear regression model for house prices prediction based on factors such as crime rates, property taxes, and the number of rooms. By exploring significant features and refining the model, this project highlights how predictive modeling can generate actionable insights in the housing market.
Main Challenge
Building a reliable model that captures the complex relationships between multiple features and house prices while ensuring robustness and generalizability to unseen data.
Project Background
This project focuses on predicting house prices using a linear regression model trained on the Boston Housing dataset. By applying rigorous data analysis techniques, the goal is to uncover the most important predictors of house prices, providing useful insights for real estate professionals and investors.
Industry Context
House prices prediction plays a vital role in industries like real estate, finance, and urban planning, where accurate forecasting helps guide investments, policy decisions, and market analysis.
Specific Challenges Faced
- Multicollinearity: High correlation between predictor variables can affect the reliability of the regression model.
- Generalization: Ensuring the model performs well on new, unseen data and avoids overfitting.
Objectives
- Develop a linear regression model that accurately predicts house prices based on the features in the Boston Housing dataset.
- Achieve an R-squared value of over 66%, ensuring the model explains a significant portion of the variance in house prices.
- Evaluate model performance on a test dataset to ensure generalizability.
- Address multicollinearity and other data issues that may impact the model’s effectiveness.
Methodology
Data Collection Process
The project uses the Boston Housing dataset from Kaggle, containing various attributes of homes and neighborhoods that influence property values. The dataset is publicly available and has been used extensively in regression analysis.
Tools and Technologies Used
- Python 3.x
- Jupyter Notebook
- Pandas for data manipulation
- Seaborn and Matplotlib for data visualization
- Scikit-learn for machine learning
- Statsmodels for statistical analysis
🏅Acknowledgment
This project leverages the work of AICHA Brihmouche, the owner of the GitHub repository CodeAlpha_Predictive_Modeling_with_Linear_Regression. The repository serves as an essential resource, offering the dataset and the notebook file that streamlines the development process.
Step-by-Step Approach
- Set up the Python environment and install necessary libraries.
- Download the Boston Housing dataset from Kaggle.
- Load and explore the dataset, including cleaning and performing exploratory data analysis (EDA); CodeAlpha_Predictive_Modeling_with_Linear_Regression
- Split the data into training and testing sets.
- Fit a linear regression model to the training data.
- Evaluate the model’s performance using metrics such as Mean Squared Error (MSE) and Root Mean Squared Error (RMSE).
- Document the findings and refine the model if necessary.
Challenges Encountered
– Feature Multicollinearity: Managing correlations between features that could affect the model’s accuracy.
– Model Generalization: Ensuring the model performs well on unseen data and avoids overfitting.
How These Were Overcome
– Addressed multicollinearity by analyzing feature correlations and selecting relevant features.


– Split the data into training and test sets to evaluate model performance on new data and avoid overfitting.
Results and Impact
- Quantifiable Outcomes
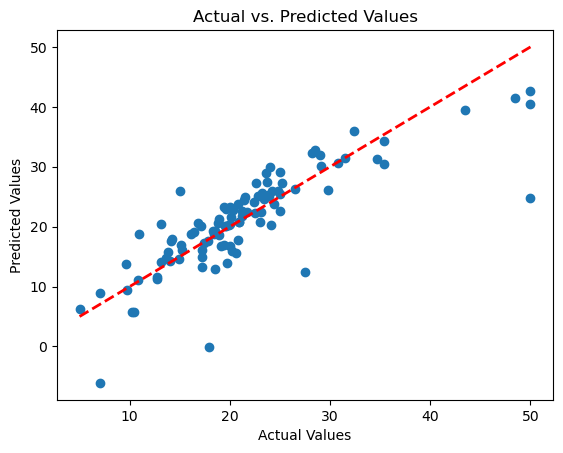
– Achieved an R-squared value of 66.9% on the test set, indicating the proportion of variance in house prices explained by the model.
– Obtained Mean Squared Error (MSE) of 24.29 and Root Mean Squared Error (RMSE) of 4.63, reflecting the model’s prediction accuracy.
- Key performance indicators (KPIs)
– Model Accuracy: Measurement of the model’s performance in predicting house prices (e.g., R-squared, MSE, RMSE).
– Feature Significance: Evaluation of which features have the most impact on house price predictions.
- Business impact
– Actionable insights: The model reveals that factors play a significant role in determining house prices. These insights can help real estate professionals prioritize neighborhoods based on the combination of these factors.
– Investment strategy: Real estate investors can use this model to identify undervalued properties in areas with potential for growth, based on key predictors.
– Urban planning: Policymakers can use the model to understand the impact of crime and infrastructure development (e.g., proximity to highways) on housing prices, guiding investment decisions in urban planning.
Lessons Learned
- Insights gained
– Model Selection: Choosing the right regression model and features significantly impacts prediction accuracy and performance.
– Feature Analysis: Thorough exploration and understanding of features are crucial for improving model effectiveness and addressing issues like multicollinearity.
- Potential for Future Applications
– Integrating more sophisticated models or ensemble methods could enhance prediction accuracy and handle more complex datasets.
– Incorporating additional features or external data sources may improve model performance and provide deeper insights into house pricing.
Conclusion
This project effectively demonstrated the application of a linear regression model for house prices prediction using the Boston Housing dataset, achieving notable performance metrics. The implementation provides valuable insights into feature significance and prediction accuracy, serving as a solid foundation for further refinement and application in real estate analytics.
🌟For more in-depth case studies and resources, explore Around Data Science hub. Dive deeper into specific topics, discover cutting-edge applications, and stay updated on the latest advancements in the field. Subscribe to our newsletter to receive regular updates and be among the first to know about exciting new resources, like our first upcoming free eBook on Artificial Intelligence for All! Don’t miss out !
Welcome to a world where data reigns supreme, and together, we’ll unravel its intricate paths



0 Comments