")
GitHub and Git for collaborative data science projects have become essential tools that revolutionize how data science teams work together. Did you know that 87% of data science projects fail to reach production, often due to poor collaboration and version control practices? This startling statistic highlights the critical need for effective collaboration frameworks in data science workflows.
Modern data science projects involve complex datasets, machine learning models, and multi-disciplinary teams working across different time zones. Traditional file-sharing methods create chaos, conflicts, and irreproducible results. However, teams that implement proper Git workflows and GitHub collaboration practices see dramatic improvements in project success rates, code quality, and team productivity.
This comprehensive guide will transform your understanding of collaborative data science workflows. You’ll discover proven strategies for organizing data science projects, implementing effective branching strategies, managing large datasets with Git LFS, and establishing robust code review processes.
Let’s dive into the world of version-controlled, reproducible, and team-friendly data science workflows.
What is GitHub and Git for Collaborative Data Science Projects?
GitHub and Git for collaborative data science projects represents a comprehensive ecosystem of tools and practices designed to enable seamless teamdriven environments. Git serves as the foundational distributed version control system that tracks changes to code, data processing scripts, and documentation over time. GitHub extends Git’s capabilities by providing a cloud-based platform that facilitates team collaboration through features like pull requests, issues tracking, and project management boards.
Unlike traditional software development, data science collaboration involves unique challenges. Teams must manage not only source code but also large datasets, trained models, Jupyter notebooks, and experimental results. The collaborative nature of data science requires coordinating work between data scientists, data engineers, machine learning engineers, and business stakeholders, each with different technical backgrounds and responsibilities.
Git’s distributed architecture allows team members to work independently on their local copies of the project while maintaining a synchronized central repository. This approach eliminates the common problem of conflicting file versions and enables parallel development on different features or experiments. GitHub’s social coding features further enhance collaboration by providing mechanisms for code review, discussion, and knowledge sharing.
The integration of version control into data science workflows ensures reproducibility, a critical requirement for scientific validity and business compliance. Every change to the codebase is tracked with detailed commit messages, making it possible to reproduce exact results from any point in the project’s history. This traceability becomes invaluable when debugging models, validating results, or meeting regulatory requirements.
Why GitHub and Git Matter for Data Science Teams
The importance of implementing proper version control and collaboration practices in data science cannot be overstated. Research indicates that teams using structured Git workflows experience significantly higher project success rates and reduced time-to-deployment. The collaborative nature of modern data science projects demands robust systems for managing concurrent work streams and maintaining project integrity.

- Enhanced Team Productivity emerges as one of the primary benefits of Git-based collaboration. When team members can work simultaneously on different aspects of a project without fear of overwriting each other’s work, overall productivity increases dramatically.
- Code Quality and Maintainability improve substantially through systematic code review processes enabled by GitHub’s pull request mechanism. Peer review catches errors early, shares knowledge across team members, and ensures adherence to coding standards. This collaborative review process is particularly valuable in data science, where complex algorithms and data transformations require multiple perspectives to validate correctness.
- Reproducibility and Auditability become manageable through Git’s comprehensive history tracking. Every change to data processing pipelines, feature engineering scripts, and model training code is documented with timestamps, authors, and detailed descriptions. This level of documentation proves essential for scientific reproducibility and regulatory compliance in industries like healthcare and finance.
- Knowledge Transfer and Onboarding processes benefit enormously from well-documented Git repositories. New team members can understand project evolution, learn from past decisions, and quickly become productive contributors. The combination of commit history, pull request discussions, and comprehensive documentation creates a rich knowledge base that preserves institutional memory.
How to Structure Data Science Projects for Collaboration

Creating an effective project structure forms the foundation of successful collaborative data science work. A well-organized repository enables team members to navigate the project intuitively, understand the codebase quickly, and contribute effectively. The structure should accommodate the unique requirements of data science workflows while maintaining simplicity and clarity.
Standard Directory Organization
Provides the scaffolding for collaborative success. The most widely adopted structure includes separate directories for raw data, processed data, source code, notebooks, models, and documentation. This separation ensures that team members understand where to find specific components and where to place new additions.
The
data/rawdirectory contains immutable original datasets, whiledata/processedholds cleaned and transformed data ready for analysis.
The notebooks directory requires special attention in collaborative environments. Organizing notebooks by analysis phase (exploratory data analysis, feature engineering, model training, evaluation) helps team members understand the project flow and locate relevant work.
Using numbered prefixes like
01-data-exploration.ipynband02-feature-engineering.ipynbcreates a clear sequence that guides newcomers through the analytical process.
Documentation Strategy
Plays a crucial role in collaborative success. Each directory should contain a README file explaining its purpose, contents, and usage guidelines. The main project README must clearly articulate the problem being solved, the approach taken, and instructions for reproducing results. This documentation serves as the primary entry point for new team members and external collaborators.
Configuration Management
Becomes critical when multiple team members work with different computing environments. Using tools like requirements.txt for Python dependencies or environment.yml for conda environments ensures that all team members can reproduce the same working environment. Container-based approaches using Docker provide even stronger guarantees of environmental consistency across different systems.
Data Management Practices
Require careful consideration in collaborative settings. Large datasets should not be stored directly in Git repositories due to size limitations and performance concerns. Instead, teams should use Git LFS (Large File Storage) for medium-sized files or establish separate data storage solutions with clear documentation about data access and versioning.
Essential Git Commands for Data Science Collaboration
Mastering fundamental Git commands enables effective participation in collaborative data science projects. These commands form the basic vocabulary for communicating changes, synchronizing work, and maintaining project integrity across team members. Understanding both individual commands and common workflows ensures smooth collaboration and reduces the likelihood of conflicts.
Repository Initialization and Cloning
Starts every collaborative project. The git clone command creates a local copy of a remote repository, establishing the connection between individual workspaces and the shared project. New repositories begin with git init, followed by connecting to a remote GitHub repository using git remote add origin.
These foundational commands establish the infrastructure for all subsequent collaboration.
Branch Management
Enables parallel development and experimentation. Creating feature branches with git checkout -b feature-name allows team members to work on specific tasks without affecting the main codebase. The git branch command lists available branches, while git switch or git checkout moves between them.
This branching strategy prevents conflicts and enables multiple experiments to proceed simultaneously.
Staging and Committing Changes
Requires understanding the Git workflow’s three-stage process. The git add command stages specific files or changes for inclusion in the next commit. The git status command provides visibility into current changes, showing modified files and staging area contents. Commits capture snapshots of work with git commit -m "descriptive message", creating permanent records in the project history.
Synchronization Commands
Maintain consistency across team members’ work. The git pull command fetches and merges changes from the remote repository, ensuring local work builds on the latest team contributions. The git push command shares local commits with the remote repository, making them available to other team members.
Regular synchronization prevents large merge conflicts and keeps everyone working with current code.
Conflict Resolution
Becomes necessary when multiple team members modify the same files. Git indicates conflicts during merge operations, marking problematic sections in affected files. Manual resolution involves choosing between conflicting changes or creating hybrid solutions that incorporate both contributions.
The
git mergeandgit rebasecommands provide different approaches to integrating changes from different branches.
Implementing Effective Branching Strategies
Successful collaborative data science projects require well-defined branching strategies that accommodate both experimentation and stability requirements. Different branching models serve different team sizes, project types, and organizational constraints. The choice of strategy significantly impacts team productivity, code quality, and project maintainability.
Git Flow Strategy provides comprehensive structure for larger teams and complex projects. This model maintains separate branches for development, features, releases, and hotfixes. The main branch contains production-ready code, while the develop branch serves as the integration point for new features. Feature branches enable individual experiments and developments, merging back to develop upon completion. This structured approach ensures stability while enabling innovation.
Feature Branching
Offers a simpler alternative suitable for smaller teams and agile workflows. Each new feature, experiment, or bug fix gets its own branch created from the main branch. Developers work independently on their feature branches, submitting pull requests when ready for integration.
- This approach reduces complexity while maintaining the benefits of isolated development and peer review.
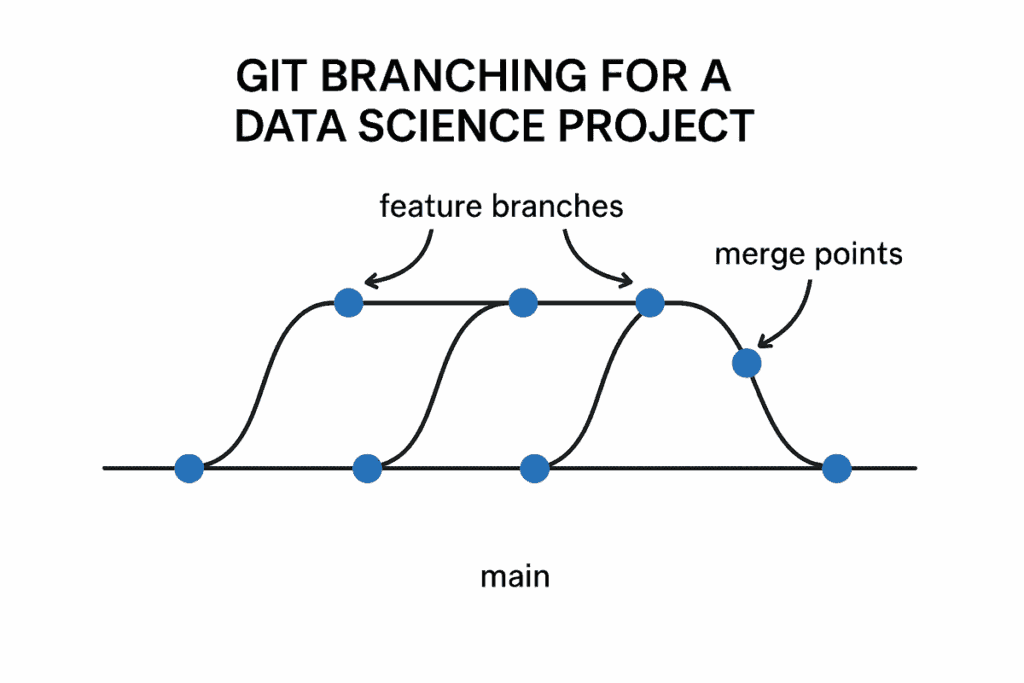
Trunk-Based Development
Suits teams emphasizing continuous integration and rapid deployment. All developers work on short-lived branches that merge frequently into the main trunk. This strategy requires strong automated testing and continuous integration practices to maintain code quality. While simpler than Git Flow, it demands higher discipline and robust quality assurance processes.
Data Science Specific Considerations
Require adaptations to traditional software development branching strategies. Experimental branches might have longer lifespans as data scientists explore different approaches and iterate on model architectures. Some experiments may never merge back to main, serving purely as research artifacts. The branching strategy should accommodate this exploratory nature while maintaining clear pathways for successful experiments to reach production.
Branch Naming Conventions
Enhance team communication and project organization. Descriptive names like feature/customer-segmentation or experiment/neural-network-approach immediately convey branch purpose. Including ticket numbers or team member initials provides additional context.
- Consistent naming conventions enable automated tooling and improve repository navigation.
Read : Python Pandas Tutorial: A Complete Guide for Beginners – Around Data Science
Managing Large Datasets with Git LFS
Data science projects frequently involve datasets that exceed Git’s recommended file size limits, creating challenges for version control and collaboration. Git Large File Storage (LFS) addresses these challenges by storing large files separately while maintaining version control integration. Understanding LFS implementation ensures that teams can collaborate effectively regardless of dataset size.
- Git LFS Architecture replaces large files with lightweight pointers in the Git repository. The actual file contents reside on specialized LFS servers, downloaded on-demand when team members access specific versions. This approach keeps Git repositories fast and manageable while preserving the benefits of version control for datasets and models.
- Installation and Setup requires adding LFS support to existing repositories. The
git lfs installcommand configures LFS for the current repository, whilegit lfs track "*.csv"specifies file patterns that should use LFS storage. The.gitattributesfile records these tracking patterns, ensuring consistent behavior across team members’ local repositories.
- Dataset Versioning Strategy becomes crucial for reproducible data science. Different versions of datasets should be clearly tagged and documented, enabling team members to reproduce results from specific time points. LFS enables this versioning without cluttering the main repository with multiple copies of large files.
- Collaboration Workflows require slight modifications when using LFS. Team members must ensure LFS is installed and configured before cloning repositories containing large files. The
git lfs pullcommand explicitly downloads LFS files, whilegit lfs pushuploads local LFS content to the remote server. These additional commands become part of the standard synchronization workflow.
- Cost and Storage Considerations influence LFS adoption decisions. GitHub provides limited free LFS storage, with additional storage available through paid plans. Teams should establish clear policies about which files justify LFS usage, balancing convenience against storage costs. Alternative solutions like external data repositories or cloud storage might be more appropriate for extremely large datasets.
Code Review Best Practices for Data Science Teams
Effective code review processes ensure quality, knowledge sharing, and team alignment in collaborative data science projects. Data science code review requires adapted approaches that account for exploratory analysis, statistical methods, and model validation procedures. Establishing systematic review practices improves both code quality and team learning outcomes.

Review Process Structure
Defines clear expectations and workflows for team members. Pull requests should include comprehensive descriptions explaining the problem being solved, the approach taken, and the expected outcomes. Reviewers need sufficient context to evaluate not just code correctness but also analytical soundness and alignment with project objectives.
Technical Review Criteria
Encompasses both software engineering and data science specific concerns. Code should be readable, well-documented, and follow established style guidelines. Data science specific criteria include statistical methodology validation, data quality checks, and model evaluation procedures.
Reviewers should verify that assumptions are clearly stated and that results are properly interpreted.
Collaborative Review Culture
Emphasizes learning and improvement over criticism. Reviews should balance constructive feedback with recognition of good practices. Team members should view reviews as opportunities to share knowledge, learn new techniques, and align on best practices.
This positive culture encourages participation and continuous improvement.
Documentation Standards
During review ensure that analytical decisions are properly recorded. Comments should explain not just what the code does, but why specific approaches were chosen. Statistical assumptions, parameter choices, and validation strategies should be clearly documented.
This documentation proves invaluable for future maintenance and knowledge transfer.
Automated Review Support
Enhances manual review processes through tooling integration. Automated linting catches style violations and common errors before human review. Continuous integration systems can run automated tests, ensuring that changes don’t break existing functionality.
These automated checks allow human reviewers to focus on higher-level concerns like methodology and business logic.
Setting Up Continuous Integration for Data Science
Continuous Integration (CI) practices adapted for data science ensure that collaborative changes maintain project quality and functionality. Data science CI encompasses traditional software testing while adding data validation, model performance monitoring, and reproducibility verification. Implementing robust CI pipelines catches problems early and enables confident collaboration.
- GitHub Actions Integration provides seamless CI/CD capabilities directly within GitHub repositories. Workflows defined in
.github/workflowsdirectories automatically trigger on specific events like pull requests or code pushes. These workflows can install dependencies, run tests, validate data quality, and deploy models, providing comprehensive quality assurance for collaborative projects. - Testing Strategy for Data Science requires adapted approaches beyond traditional unit testing. Data validation tests verify that input datasets meet expected schema and quality requirements. Model performance tests ensure that changes don’t degrade predictive accuracy below acceptable thresholds. Integration tests validate that entire pipelines produce expected outputs given standard inputs.
- Environment Consistency becomes critical for reliable CI execution. Containerized environments using Docker ensure that CI systems exactly match development environments. Dependency management through requirements files or environment specifications guarantees that all team members and CI systems work with identical package versions.
- Performance Monitoring tracks computational efficiency and resource usage. CI pipelines should monitor execution times, memory usage, and model training duration to detect performance regressions. This monitoring helps teams identify when changes introduce inefficiencies that could impact production deployments.
- Deployment Automation extends CI into continuous deployment for approved changes. Successful CI runs can automatically deploy models to staging environments for further testing. Production deployments might require manual approval but can leverage the same automated processes validated during CI execution.
See : Python for Data Science: 5 Free Certification Courses You Can’t Miss
Collaborative Jupyter Notebook Management
Jupyter notebooks present unique challenges for collaborative data science work due to their mixed content format and execution state dependencies. Effective notebook collaboration requires adapted workflows, clear conventions, and specialized tooling to maintain quality and enable meaningful peer review. Mastering notebook collaboration ensures that exploratory analysis remains accessible and reproducible.

Notebook Organization Strategy provides structure for collaborative notebook development. Sequential numbering and descriptive names help team members understand analysis flow and locate relevant work. Each notebook should focus on a specific aspect of the analysis, avoiding monolithic notebooks that become difficult to review and maintain.
Version Control Challenges arise from notebooks’ JSON format and embedded output data. Raw notebook diffs are difficult to interpret, making meaningful code review challenging. Solutions include clearing outputs before committing, using specialized diff tools like nbdime, or converting notebooks to script format for version control while maintaining notebook versions for interactive work.
Cell Execution Dependencies create reproducibility challenges when team members run notebooks in different orders or with different kernels. Best practices include writing notebooks that can execute completely from top to bottom, avoiding hidden state dependencies, and clearly documenting any required setup or data preparation steps.
Output Management requires careful consideration of what should be version controlled. Including outputs makes diffs noisy and repositories large, but provides immediate visibility into results. Many teams adopt policies of clearing outputs before committing while maintaining separate result artifacts for documentation and presentation purposes.
Collaborative Review Processes must account for notebooks’ unique characteristics. Reviewers should evaluate both code quality and analytical soundness, checking that conclusions are supported by the presented evidence. GitHub’s rich notebook rendering capabilities enable effective visual review of charts, tables, and markdown explanations.
Explore : Jupyter for Beginners: The Easy Way to Start Coding – Around Data Science
5 Bonus Tips for GitHub and Git Collaborative Data Science
These advanced strategies will elevate your collaborative data science workflows beyond basic version control, enabling sophisticated team coordination and project management capabilities that distinguish professional teams from amateur efforts.
Issue-Driven Development
Transforms GitHub Issues into powerful project management tools. Create issues for each analytical task, model experiment, or bug fix, using labels to categorize by priority, complexity, and project area. Link pull requests to issues using keywords like “Closes #42” to automatically track progress and maintain clear connections between problems and solutions. This approach provides transparent project visibility and enables effective workload distribution across team members.
Advanced Merge Strategies
Optimize collaboration workflows for different team dynamics. Interactive rebasing with git rebase -i enables cleaning up commit history before sharing, creating clean, logical progression through analytical work. Squash merging consolidates feature branch commits into single, cohesive contributions, while merge commits preserve complete development history. Choose strategies based on team preferences and project documentation requirements.
Automated Documentation Generation
Maintains up-to-date project documentation without manual overhead. Tools like Sphinx for Python or roxygen2 for R automatically generate API documentation from code comments. GitHub Actions can rebuild documentation on every commit, ensuring that team members always access current information. This automation removes barriers to comprehensive documentation and improves knowledge sharing.
Cross-Repository Coordination
Manages complex projects spanning multiple repositories. Use Git submodules to include shared libraries or datasets as versioned dependencies. GitHub’s dependency graph features track connections between repositories, enabling impact analysis when changes occur in shared components. This approach enables modular project architecture while maintaining coordination across components.
Security and Access Management
Protects sensitive data and intellectual property. GitHub’s branch protection rules prevent direct pushes to main branches, requiring pull request review for all changes. Secret scanning automatically detects accidentally committed credentials or API keys. Fine-grained access controls ensure that team members have appropriate permissions while external collaborators remain limited to specific project areas.
Check : Enhancing Real-Time Object Detection: Implementing YOLOv4-Tiny with OpenCV – Around Data Science
Conclusion for GitHub and Git Collaborative Data Science Projects
Effective collaboration through GitHub and Git for collaborative data science projects transforms how teams approach complex analytical challenges and deliver business value. Key takeaways for successful implementation include:
- Establish clear project structure with standardized directories, documentation practices, and dependency management to enable seamless team coordination
- Implement appropriate branching strategies that balance experimentation freedom with code stability, adapted to your team size and project requirements
- Master essential Git workflows including branching, merging, and conflict resolution to enable confident parallel development across team members
- Adopt systematic code review practices that emphasize both technical quality and analytical soundness, fostering continuous learning and knowledge sharing
- Leverage continuous integration with automated testing, data validation, and deployment pipelines to maintain project quality throughout collaborative development
- Manage large datasets effectively using Git LFS and external storage solutions while preserving version control benefits for reproducible research
- Optimize notebook collaboration through clear organization, output management, and specialized review processes adapted to Jupyter’s unique characteristics
The combination of these practices enables data science teams to achieve higher success rates, improved reproducibility, and accelerated delivery of business insights.
So, mastering GitHub and Git for collaborative data science projects empowers Algerian data scientists to compete effectively in the global marketplace while building sustainable, professional-grade analytical capabilities that drive organizational success.
Start your journey to become a data-savvy professional in Algeria.
👉 Subscribe to our newsletter, follow Around Data Science on LinkedIn, and join the discussion on Discord.


